1/ Kubernetes in 5 Minutes
To me, the areas that Kubernetes natively accounts for in logical — imo — order are:
Hardware – Node
Orchestration – Deployment, Job, CronJob, StatefulSet, DaemonSet
Configuration – ConfigMap, Secret
Persistence — PersistentVolumeClaim, PersistentVolume
Execution – Pod, ReplicaSet
Access Control – Namespace, ServiceAccount, Role, ClusterRole
Exposure – Service, Ingress
Hardware
All software has one fundamental dependency: a machine to run on. We need hardware whether it’s our own computers or someone else’s and this abstraction comes in the form of a Node resource type.
Node: Represents a logical machine/VM (eg. your computer, ec2 instance, a droplet).
Orchestration
After we’ve defined our hardware, we need a plan on how to deploy our application. Will it be a single instance? Do we need maybe two? When we need to update our application, should it be done one by one or all at once? Do we want it to be deployed across all our Nodes? Should it be run once every day at 3 AM? We need to orchestrate the deployment.
Deployment: Long-standing workloads (eg. a server)
Job: One-off workload (eg. a shell script/database migration task)
CronJob: Periodically-run one-off workload (eg. data sync task)
StatefulSet: Workloads that require a readable/writable data volume (hard disk) that persists beyond restarts and is not shared amongst other instances of the same application. Use cases include services that implement eventual consistency (eg. transactional databases)
DaemonSet: Workloads that should be distributed across all targeted Nodes (eg. log collectors, system monitors, security software)
Configuration
So we’ve got a plan, but applications tend to be a fickle bunch and also need to be told certain things at runtime instead of plan-time; Things such as which network interface to bind to, which port to listen on, which API keys to use et cetera. While these things can technically be hard-coded, best-practices of 2020 generally suggest they should not. So we need a way to configure our application at runtime.
ConfigMap: Stores configuration for mounting as environment variables or read-only files (eg.
SERVER_PORT=8080)Secret: Fundamentally the same but stored in Base64 encoded text and used for values that should not be stored in plaintext (eg.
GITHUB_API_TOKEN=😱)
Persistence
Now what if our application handles files and requires a hard disk that it can read and write from across different versions and instances? We need our data to persist by providing our application’s system with a hard disk (AKA volume in technical terms).
PersistentVolume: A logical “hard drive” (eg. Seagate 2TB, EBS)
PersistentVolumeClaim: Binds a PersistentVolume to a Pod. This is more of a virtual construct: think of it as the act of mounting a hard drive. A PVC defines that intention to mount a hard drive and expose its filesystem for an application to use.
Execution
So we’ve defined how our application will be deployed and configured, and we’ve given it some hard disk space to use. All that’s left now is to execute the application.
Pod: One instance of your application (eg.
npm start,go run ./...)ReplicaSet: Maintains the desired count of your application instances.
Access Control
But what if someone accidentally introduced a nasty virus into our application (somehow)? In an enterprise environment with compliance teams nagging at the whole DevOps thingy, we need to ensure that applications can only access resources that it needs to access. We on the other hand, need access control.
Namespace: Defines a virtual boundary within a cluster for access control mechanisms to be implemented on top of. Think about these like browser tabs: an open Facebook tab shouldn’t know what you’re googling in another tab.
ServiceAccount: Defines a virtual user that can be assigned a Role or ClusterRole which contains a set of permissions scoped to a set of resources (eg. your user login on your machine)
Role: Defines namespace-scoped resource access permissions. Linked to a ServiceAccount with namespace-scoped access via a RoleBinding resource
ClusterRole: Defines cluster-wide resource access permissions. Linked to a ServiceAccount with cluster-wide access via a ClusterRoleBinding resource
Exposure
Finally, there’s no use of an application that no one can access. After we’ve made the application happy and it’s running as expected, we expose it to the rest of the network/public internet for users and other services to access it.
Service: Exposes a workload to the cluster. Think running
npm starton a server application and your application being available onlocalhost:3000. Behind the scenes, your application is binding to a port on your computer. A Service defines that binding.Ingress: Exposes a Service to outside the cluster. Ever tried asking your co-worker to access your
localhost:3000? Chances are you’d have ended up usingngrokor a similar tunneling software. An Ingress is basically anngrokthat exposes yourlocalhost:3000so it becomes accessible to a larger network.
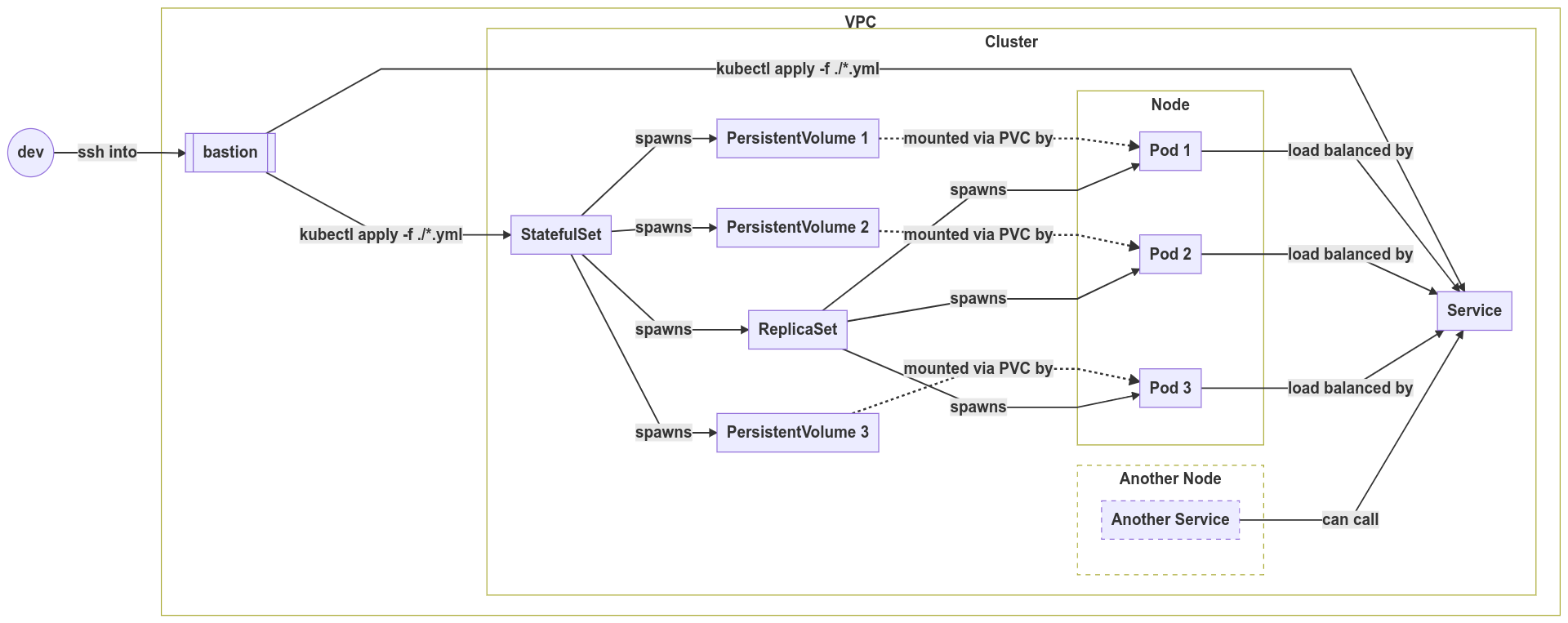
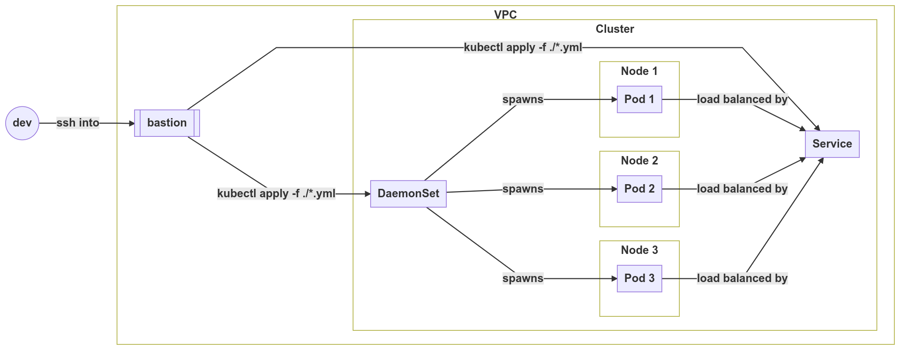
Linking It All Up —Some Common Deployment Patterns
They said a picture is worth a thousand words. So here’s some diagrams to visualise how all the above links up.
An HTTP-based API server

A periodic job

An eventually consistent database system
A cloud-monitoring agent
![]()
Last updated